Per soddisfare le esigenze dei servizi cloud, la rete si sta gradualmente suddividendo in Underlay e Overlay. La rete Underlay è costituita dalle apparecchiature fisiche, come router e switch, presenti nei data center tradizionali, che si basano ancora sul concetto di stabilità e forniscono capacità di trasmissione dati di rete affidabili. La rete Overlay è la rete aziendale incapsulata al di sopra di essa, più vicina al servizio, che, tramite l'incapsulamento con protocolli VXLAN o GRE, offre agli utenti servizi di rete di facile utilizzo. Le reti Underlay e Overlay sono correlate ma disaccoppiate, pur essendo interconnesse e in grado di evolversi in modo indipendente.
La rete Underlay è il fondamento della rete. Se la rete Underlay è instabile, non è possibile garantire l'accordo sul livello di servizio (SLA) per l'azienda. Dopo l'architettura di rete a tre livelli e l'architettura di rete Fat-Tree, l'architettura di rete dei data center sta passando all'architettura Spine-Leaf, che ha inaugurato la terza applicazione del modello di rete CLOS.
Architettura di rete tradizionale dei data center
Design a tre strati
Dal 2004 al 2007, l'architettura di rete a tre livelli è stata molto diffusa nei data center. Essa è composta da tre livelli: il livello core (la dorsale di commutazione ad alta velocità della rete), il livello di aggregazione (che fornisce connettività basata su policy) e il livello di accesso (che collega le workstation alla rete). Il modello è il seguente:
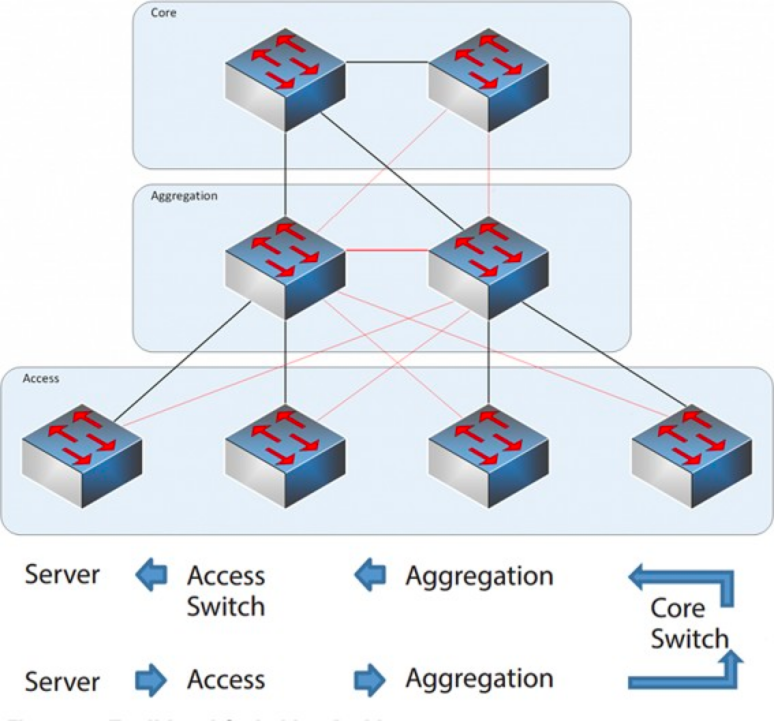
Architettura di rete a tre livelli
Livello centrale: gli switch centrali forniscono l'inoltro ad alta velocità dei pacchetti in entrata e in uscita dal data center, la connettività ai molteplici livelli di aggregazione e una rete di routing L3 resiliente che in genere serve l'intera rete.
Livello di aggregazione: lo switch di aggregazione si connette allo switch di accesso e fornisce altri servizi, come firewall, offload SSL, rilevamento delle intrusioni, analisi di rete, ecc.
Livello di accesso: gli switch di accesso si trovano solitamente nella parte superiore del rack, per questo sono anche chiamati switch ToR (Top of Rack), e si collegano fisicamente ai server.
In genere, lo switch di aggregazione rappresenta il punto di demarcazione tra le reti L2 e L3: la rete L2 si trova al di sotto dello switch di aggregazione, mentre la rete L3 si trova al di sopra. Ogni gruppo di switch di aggregazione gestisce un Point of Delivery (POD), e ogni POD costituisce una rete VLAN indipendente.
Protocollo Network Loop e Spanning Tree
La formazione di loop è causata principalmente dalla confusione generata da percorsi di destinazione poco chiari. Quando gli utenti progettano reti, per garantire l'affidabilità, utilizzano solitamente dispositivi e collegamenti ridondanti, il che porta inevitabilmente alla formazione di loop. La rete di livello 2 si trova nello stesso dominio di broadcast e i pacchetti broadcast vengono ritrasmessi ripetutamente all'interno del loop, generando una tempesta di broadcast che può causare il blocco delle porte e la paralisi delle apparecchiature in un istante. Pertanto, per prevenire le tempeste di broadcast, è necessario impedire la formazione di loop.
Per prevenire la formazione di loop e garantire l'affidabilità, è possibile trasformare i dispositivi e i collegamenti ridondanti in dispositivi e collegamenti di backup. In altre parole, le porte e i collegamenti dei dispositivi ridondanti sono bloccati in condizioni normali e non partecipano all'inoltro dei pacchetti di dati. Solo in caso di guasto del dispositivo, della porta o del collegamento di inoltro corrente, con conseguente congestione della rete, le porte e i collegamenti dei dispositivi ridondanti vengono aperti, consentendo il ripristino della normale operatività della rete. Questo controllo automatico è implementato dal protocollo Spanning Tree (STP).
Il protocollo Spanning Tree (STP) opera tra il livello di accesso e il livello di destinazione e, al suo interno, si trova un algoritmo Spanning Tree in esecuzione su ogni bridge abilitato per STP, specificamente progettato per evitare loop di bridging in presenza di percorsi ridondanti. STP seleziona il percorso dati migliore per l'inoltro dei messaggi e blocca i collegamenti che non fanno parte dello Spanning Tree, lasciando attivo un solo percorso tra due nodi di rete qualsiasi, mentre l'altro collegamento in uplink viene bloccato.
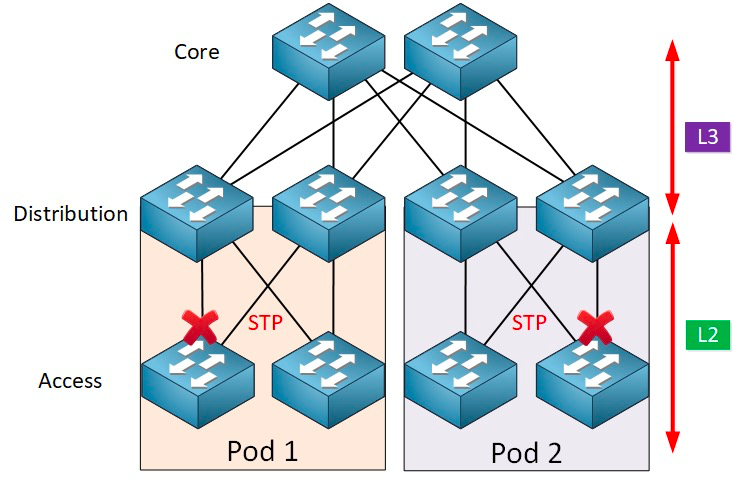
STP offre numerosi vantaggi: è semplice, plug-and-play e richiede una configurazione minima. Le macchine all'interno di ciascun pod appartengono alla stessa VLAN, quindi il server può migrare la propria posizione all'interno del pod in modo arbitrario senza modificare l'indirizzo IP e il gateway.
Tuttavia, i percorsi di inoltro paralleli non possono essere utilizzati da STP, che disabiliterà sempre i percorsi ridondanti all'interno della VLAN. Svantaggi di STP:
1. Convergenza lenta della topologia. Quando la topologia di rete cambia, il protocollo Spanning Tree impiega 50-52 secondi per completare la convergenza della topologia.
2. Non è in grado di fornire la funzione di bilanciamento del carico. Quando si verifica un loop nella rete, il protocollo Spanning Tree può solo bloccare il loop, impedendo così al collegamento di inoltrare i pacchetti di dati e sprecando risorse di rete.
Virtualizzazione e sfide del traffico est-ovest
Dopo il 2010, al fine di migliorare l'utilizzo delle risorse di calcolo e di archiviazione, i data center hanno iniziato ad adottare la tecnologia di virtualizzazione e un gran numero di macchine virtuali ha cominciato a comparire nella rete. La tecnologia di virtualizzazione trasforma un server in più server logici, ognuno dei quali può essere eseguito in modo indipendente, ha il proprio sistema operativo, le proprie applicazioni, il proprio indirizzo MAC e indirizzo IP indipendenti e si connette all'esterno tramite uno switch virtuale (vSwitch) all'interno del server.
La virtualizzazione ha un requisito complementare: la migrazione live delle macchine virtuali, ovvero la capacità di spostare un sistema di macchine virtuali da un server fisico a un altro mantenendo il normale funzionamento dei servizi sulle macchine virtuali. Questo processo non ha alcun impatto sugli utenti finali: gli amministratori possono allocare le risorse del server in modo flessibile, oppure riparare e aggiornare i server fisici senza interrompere il normale utilizzo da parte degli utenti.
Per garantire che il servizio non venga interrotto durante la migrazione, è necessario che non solo l'indirizzo IP della macchina virtuale rimanga invariato, ma anche che il suo stato di esecuzione (come lo stato della sessione TCP) venga mantenuto durante la migrazione. Pertanto, la migrazione dinamica della macchina virtuale può essere eseguita solo all'interno dello stesso dominio di livello 2, ma non tra domini di livello 2 diversi. Ciò crea la necessità di domini di livello 2 più ampi, dal livello di accesso al livello core.
Nella tradizionale architettura di rete di livello 2 di grandi dimensioni, il punto di divisione tra L2 e L3 si trova nello switch di core, e il data center al di sotto dello switch di core costituisce un dominio di broadcast completo, ovvero la rete L2. In questo modo, è possibile realizzare la distribuzione arbitraria dei dispositivi e la migrazione della posizione, senza la necessità di modificare la configurazione di IP e gateway. Le diverse reti L2 (VLAN) vengono instradate attraverso gli switch di core. Tuttavia, in questa architettura, lo switch di core deve gestire un'enorme tabella MAC e ARP, il che impone requisiti elevati in termini di capacità. Inoltre, anche lo switch di accesso (TOR) limita la scalabilità dell'intera rete. Ciò comporta limitazioni in termini di scalabilità, espansione e capacità elastica della rete, e problemi di latenza tra i tre livelli di pianificazione non consentono di soddisfare le esigenze aziendali future.
D'altro canto, il traffico est-ovest generato dalla tecnologia di virtualizzazione pone anche delle sfide alla tradizionale rete a tre livelli. Il traffico dei data center può essere suddiviso nelle seguenti categorie principali:
Traffico nord-sud:Traffico tra client esterni al data center e il server del data center, oppure traffico dal server del data center verso Internet.
Traffico est-ovest:Traffico tra server all'interno di un data center, nonché traffico tra data center diversi, come ad esempio il ripristino di emergenza tra data center e la comunicazione tra cloud privati e pubblici.
L'introduzione della tecnologia di virtualizzazione rende la distribuzione delle applicazioni sempre più distribuita, e l'effetto collaterale è un aumento del traffico est-ovest.
Le tradizionali architetture a tre livelli sono in genere progettate per il traffico in direzione nord-sud.Sebbene possa essere utilizzato per il traffico est-ovest, alla fine potrebbe non funzionare come previsto.
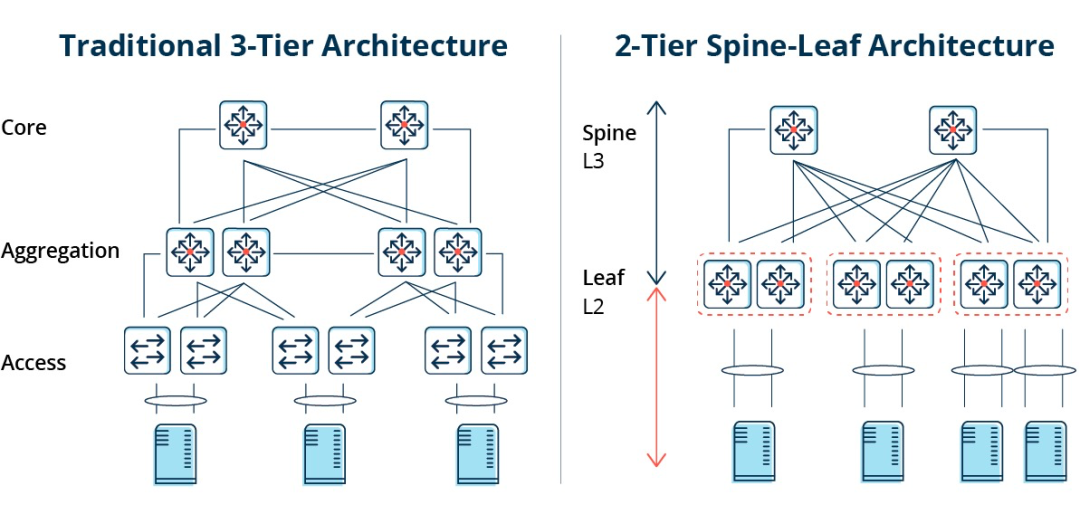
Architettura tradizionale a tre livelli contro architettura a spina dorsale e foglie
In un'architettura a tre livelli, il traffico est-ovest deve essere inoltrato attraverso dispositivi negli strati di aggregazione e core, passando inutilmente attraverso numerosi nodi. (Server -> Accesso -> Aggregazione -> Switch Core -> Aggregazione -> Switch di Accesso -> Server)
Pertanto, se un grande volume di traffico est-ovest attraversa una tradizionale architettura di rete a tre livelli, i dispositivi collegati alla stessa porta dello switch potrebbero competere per la larghezza di banda, con conseguenti tempi di risposta scadenti per gli utenti finali.
Svantaggi dell'architettura di rete tradizionale a tre livelli
Si può notare che la tradizionale architettura di rete a tre livelli presenta numerose lacune:
Spreco di larghezza di banda:Per evitare la formazione di loop, il protocollo STP viene solitamente eseguito tra il livello di aggregazione e il livello di accesso, in modo che solo un collegamento uplink dello switch di accesso trasporti effettivamente traffico, mentre gli altri collegamenti uplink vengono bloccati, con conseguente spreco di larghezza di banda.
Difficoltà nel posizionamento di reti su larga scala:Con l'espansione delle dimensioni della rete, i data center sono distribuiti in diverse posizioni geografiche, le macchine virtuali devono essere create e migrate ovunque, e i loro attributi di rete, come indirizzi IP e gateway, rimangono invariati, il che richiede il supporto di un livello 2 "fat". Nella struttura tradizionale, non è possibile effettuare alcuna migrazione.
Assenza di traffico est-ovest:L'architettura di rete a tre livelli è progettata principalmente per il traffico Nord-Sud, sebbene supporti anche il traffico Est-Ovest, ma presenta evidenti limitazioni. Quando il traffico Est-Ovest è elevato, la pressione sugli switch del livello di aggregazione e del livello centrale aumenta notevolmente, e le dimensioni e le prestazioni della rete risultano limitate a questi ultimi.
Questo pone le imprese di fronte al dilemma tra costi e scalabilità:Il supporto di reti ad alte prestazioni su larga scala richiede un gran numero di apparecchiature per lo strato di convergenza e per lo strato centrale, il che non solo comporta costi elevati per le aziende, ma richiede anche una pianificazione anticipata della rete durante la fase di costruzione. Quando la rete è di piccole dimensioni, si verifica uno spreco di risorse, mentre quando la rete continua ad espandersi, diventa difficile gestirne l'espansione.
L'architettura a rete spinale-foglia
Che cos'è l'architettura di rete Spine-Leaf?
In risposta ai problemi di cui sopra,È emerso un nuovo modello di data center, l'architettura di rete Spine-Leaf, che chiamiamo rete leaf-ridge.
Come suggerisce il nome, l'architettura presenta un livello Spine e un livello Leaf, che includono switch Spine e switch Leaf.
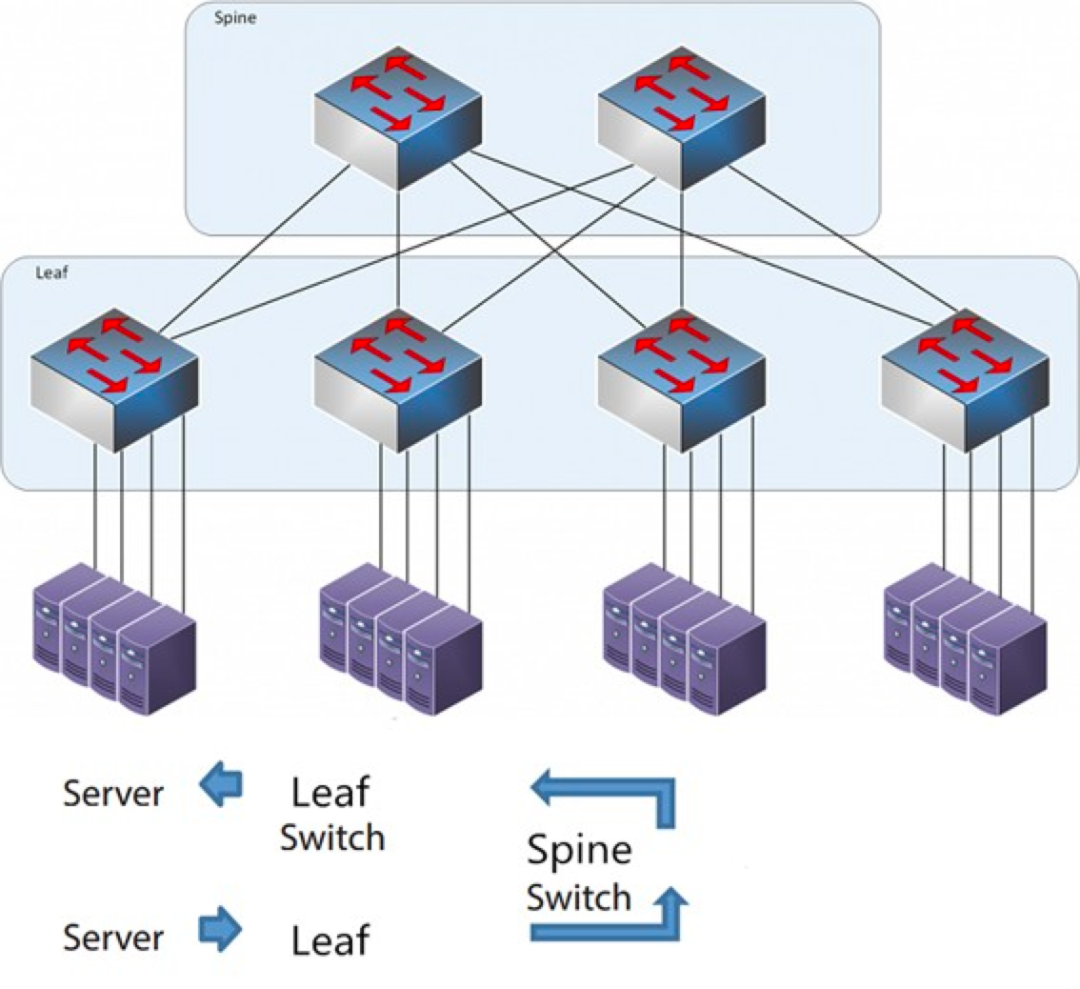
L'architettura della spina dorsale
Ciascun interruttore a foglia è collegato a tutti gli interruttori a cresta, che non sono collegati direttamente tra loro, formando una topologia a maglia completa.
In un'architettura spine-and-leaf, una connessione da un server a un altro passa attraverso lo stesso numero di dispositivi (Server -> Leaf -> Spine Switch -> Leaf Switch -> Server), garantendo una latenza prevedibile. Questo perché un pacchetto deve attraversare solo uno switch spine e un altro switch leaf per raggiungere la destinazione.
Come funziona Spine-Leaf?
Switch Leaf: è equivalente allo switch di accesso nella tradizionale architettura a tre livelli e si collega direttamente al server fisico come TOR (Top Of Rack). La differenza rispetto allo switch di accesso è che il punto di demarcazione della rete L2/L3 si trova ora sullo switch Leaf. Lo switch Leaf si trova al di sopra della rete a 3 livelli e al di sotto del dominio di broadcast L2 indipendente, risolvendo il problema BUM (Broadcast Unified Monitoring) delle grandi reti a 2 livelli. Se due server Leaf devono comunicare, devono utilizzare il routing L3 e inoltrarlo attraverso uno switch Spine.
Switch Spine: Equivalente a uno switch core. ECMP (Equal Cost Multi Path) viene utilizzato per selezionare dinamicamente più percorsi tra gli switch Spine e Leaf. La differenza è che lo switch Spine ora fornisce semplicemente una rete di routing L3 resiliente per lo switch Leaf, in modo che il traffico nord-sud del data center possa essere instradato dallo switch Spine anziché direttamente. Il traffico nord-sud può essere instradato dallo switch edge parallelo allo switch Leaf al router WAN.
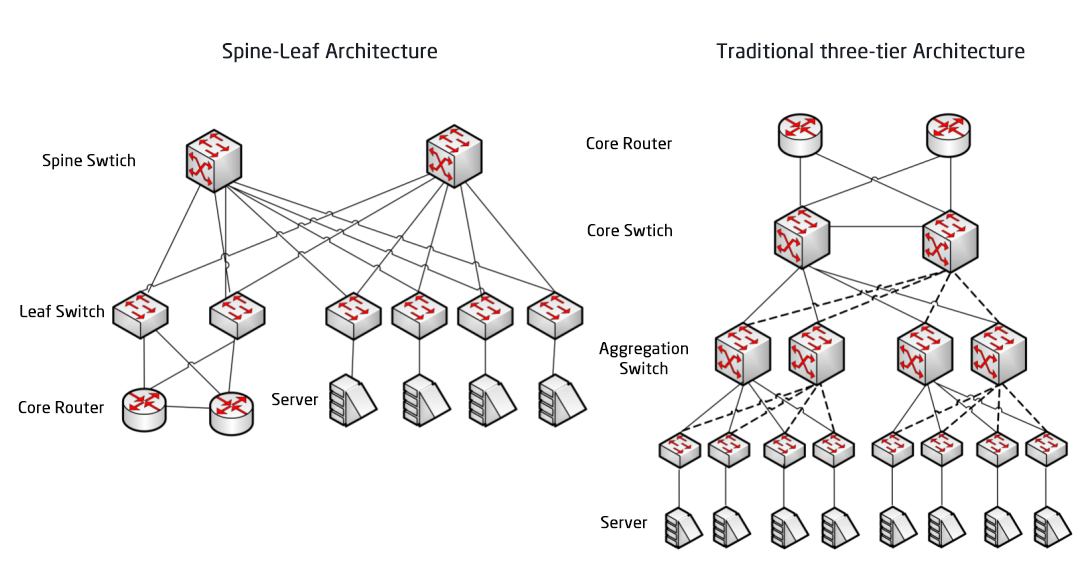
Confronto tra l'architettura di rete Spine/Leaf e la tradizionale architettura di rete a tre strati.
Vantaggi della foglia spinata
Piatto:Un design piatto accorcia il percorso di comunicazione tra i server, con conseguente riduzione della latenza, il che può migliorare significativamente le prestazioni di applicazioni e servizi.
Buona scalabilità:Quando la larghezza di banda è insufficiente, è possibile estenderla orizzontalmente aumentando il numero di switch Ridge. Se la densità di porte è insufficiente, all'aumentare del numero di server è possibile aggiungere switch Leaf.
Riduzione dei costi: traffico in direzione nord e sud, in uscita dai nodi foglia o dai nodi cresta. Flusso est-ovest, distribuito su percorsi multipli. In questo modo, la rete foglia-cresta può utilizzare switch a configurazione fissa senza la necessità di costosi switch modulari, riducendo così i costi.
Bassa latenza e prevenzione della congestione:In una rete Leaf Ridge, i flussi di dati compiono lo stesso numero di hop attraverso la rete, indipendentemente dalla sorgente e dalla destinazione, e due server qualsiasi sono raggiungibili l'uno dall'altro con un percorso di tre hop (Leaf -> Spine -> Leaf). Questo crea un percorso di traffico più diretto, che migliora le prestazioni e riduce i colli di bottiglia.
Elevata sicurezza e disponibilità:Il protocollo STP viene utilizzato nella tradizionale architettura di rete a tre livelli e, quando un dispositivo si guasta, si verifica una riconvergenza che influisce sulle prestazioni della rete o può addirittura causarne il blocco. Nell'architettura leaf-ridge, invece, quando un dispositivo si guasta, non è necessaria la riconvergenza e il traffico continua a transitare attraverso altri percorsi normali. La connettività di rete non viene compromessa e la larghezza di banda viene ridotta solo da un singolo percorso, con un impatto minimo sulle prestazioni.
Il bilanciamento del carico tramite ECMP è particolarmente adatto ad ambienti in cui vengono utilizzate piattaforme di gestione di rete centralizzate come SDN. SDN consente di semplificare la configurazione, la gestione e il reindirizzamento del traffico in caso di blocco o guasto del collegamento, rendendo la topologia full mesh con bilanciamento del carico intelligente relativamente semplice da configurare e gestire.
Tuttavia, l'architettura Spine-Leaf presenta alcune limitazioni:
Uno svantaggio è che l'aumento del numero di switch incrementa le dimensioni della rete. Il data center con architettura di rete leaf-ridge deve incrementare il numero di switch e apparecchiature di rete in proporzione al numero di client. Con l'aumentare del numero di host, è necessario un numero maggiore di switch leaf per il collegamento allo switch ridge.
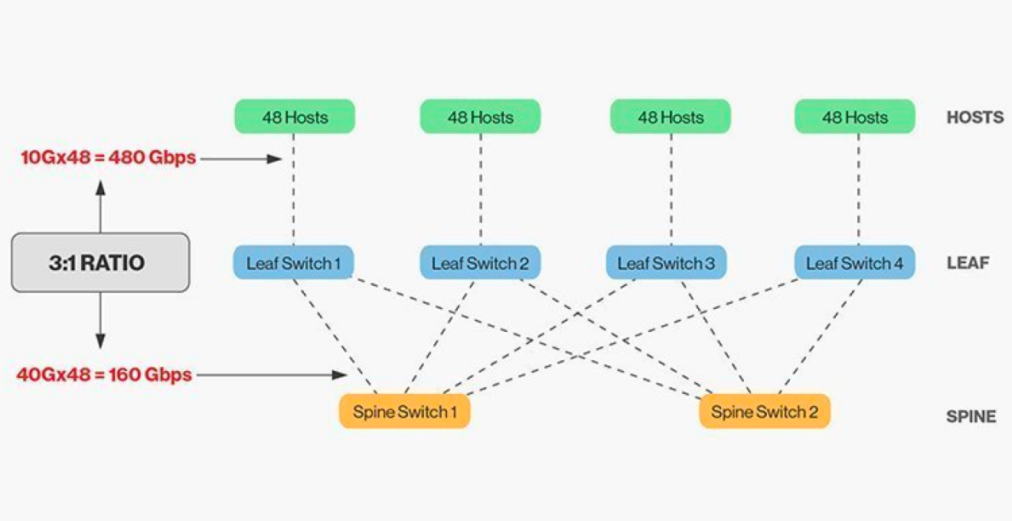
L'interconnessione diretta degli switch di cresta e di foglia richiede un accoppiamento preciso e, in generale, il rapporto di larghezza di banda accettabile tra switch di foglia e di cresta non può superare 3:1.
Ad esempio, su uno switch leaf sono presenti 48 client con velocità di 10 Gbps e una capacità totale di porte pari a 480 Gb/s. Se le quattro porte uplink da 40 Gb di ciascuno switch leaf vengono collegate allo switch ridge da 40 G, la capacità uplink sarà di 160 Gb/s. Il rapporto è quindi 480:160, ovvero 3:1. Gli uplink dei data center sono in genere da 40 Gb o 100 Gb e possono essere migrati nel tempo da un punto di partenza di 40 Gb (Nx 40 Gb) a 100 Gb (Nx 100 Gb). È importante notare che l'uplink deve sempre funzionare a una velocità superiore rispetto al downlink per evitare di bloccare il collegamento tra le porte.
Le reti Spine-Leaf presentano anche requisiti di cablaggio specifici. Poiché ogni nodo leaf deve essere connesso a ogni switch spine, è necessario posare un numero maggiore di cavi in rame o in fibra ottica. La distanza di interconnessione incide sui costi. A seconda della distanza tra gli switch interconnessi, il numero di moduli ottici di fascia alta richiesti dall'architettura Spine-Leaf è decine di volte superiore a quello della tradizionale architettura a tre livelli, il che aumenta il costo complessivo di implementazione. Tuttavia, ciò ha portato alla crescita del mercato dei moduli ottici, in particolare per i moduli ottici ad alta velocità come 100G e 400G.
Data di pubblicazione: 26 gennaio 2026



